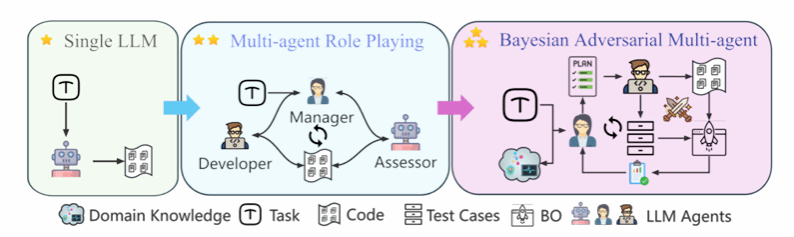
在大语言模型的助推之下,从模拟仿真到数据分析,AI正在帮助科研人员自动写代码。但现实是,领域科学家往往缺乏计算机背景,写出的提示词模糊不清、隐含大量专业假设;科学计算流程复杂,一个小错误就能引发连锁反应;更致命的是,大模型会产生“幻觉”——输出看起来合理,实则暗藏致命缺陷。
在多智能体协作中,一个环节的错误会被下游无条件接受,层层放大。现有的提示优化和自我修正技术面对这种微妙的错误模式往往束手无策。科学家们迫切需要可靠的代码,却困在“不会写好提示词”的尴尬境地。这一困境直接制约了AI4S(AI for Science, 科学智能)研究的普惠化进程,大量关键科学问题因较高的技术门槛而无法被AI有效赋能。
为此,复旦大学人工智能创新与产业研究院(下称“AI³院”)、上海科学智能研究院(下称“上智院”)、上海创智学院的联合研究团队提出了一种贝叶斯对抗式多智能体框架,用一种全新的思路解决上述难题。该框架不依赖单一模型的自我修正能力,而是通过多角色分工与对抗博弈,让系统在持续的“攻防演练”中自发涌现出更高的代码质量。

论文标题|AI-for-Science Low-code Platform with Bayesian Adversarial Multi-Agent Framework
论文地址|https://openreview.net/forum?id=Cug26Y0RlT
相关论文已被ICLR 2026接收。复旦大学AI³院及上海创智学院博士生曾子航、张家铨,为共同第一作者;AI³院教授、上智院AI科学家陈曦,为本文通讯作者;复旦大学特聘教授、AI³院院长、上智院首席科学家漆远,为本文共同作者。
框架的核心是一个“出题人vs答题人”的对抗循环。任务管理器(TM)扮演“出题人”,负责设计具有挑战性的测试用例,不断探测当前代码的边界;方案生成器(SG)扮演“答题人”,根据测试反馈持续改进代码;评估器(Eval)则担任“裁判”,对双方表现进行客观打分。两者在对抗中共同进化,出题人越出越精,答题人越答越好。
更关键的是,框架引入了贝叶斯更新机制。每一次迭代后,系统会根据得分动态调整测试用例和代码方案的概率分布,自动聚焦最有价值的探索方向。通俗来讲就是,每一次迭代都让系统更聪明地选择最有价值的测试和代码组合,而不是盲目尝试。这种机制将“试错”转化为了“有指导的探索”——系统不会在已经验证无效的方向上浪费时间,而是像经验丰富的研究者一样,根据已有证据不断缩小搜索范围,逐步逼近最优解。
(三种代码生成范式对比)
该框架的第一大贡献在于:提出了一种面向AI4S的低代码平台,结合贝叶斯对抗式递归代码生成机制,显著提升 AI4S项目的代码生成可靠性。与传统多智能体系统完全依赖大模型做决策不同,本低代码平台采用非大模型的对抗性评分机制,从根本上降低了对基础模型智能水平的依赖。同时,框架让不懂编程的科学家只需用自然语言描述研究需求,系统即可辅助生成更高质量的科研代码。
在SciCode基准测试中,8B模型使用该框架后性能相对提升87.1%(子问题求解率从13.2%跃升至24.7%);
32B 开源模型配合该框架,在SciCode上达到33.0%的求解率,直接超越了235B模型的基线表现(30.6%)——小模型逆袭大模型;
在ScienceAgentBench上,框架达到90.2%的有效执行率,刷新当前最佳(SOTA)纪录。
这些数字背后反映的是一个关键趋势:通过合理的框架设计,开源小模型完全可以在特定科学任务上匹敌甚至超越商业大模型,这为科研团队降低算力成本提供了切实可行的路径。
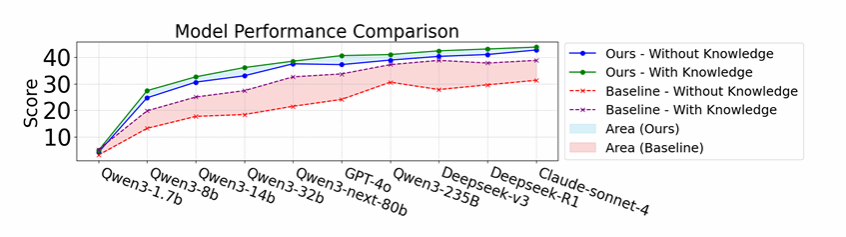
更值得注意的是,框架对提示词质量展现出极强的鲁棒性。研究团队对比了“基础提示”和“专家精心编写提示”两种条件下的表现:基线模型的性能差距巨大,严重依赖提示词质量;而使用该框架后,这一差距被大幅压缩。即使用户只提供基础描述,框架的表现依然大幅超越专家提示词的基线模型。
这验证了框架的第二大贡献:显著提升编码智能体性能,且不受基础模型能力限制。未来,该框架有望扩展至更多科学计算场景,为AI4S生态提供更广泛且可靠的技术支撑。
在这种贝叶斯对抗式多智能体框架的助力之下,更多领域专家能够借助AI工具高效开展科研工作。比如,当一位海洋学家只需用自然语言描述研究问题,系统就能通过多轮对抗迭代生成更可靠的科研代码。随着这一范式的推广,更多领域的研究者能够专注于科学问题核心,而非陷入编程细节,从而加速AI与基础科学的深度融合。
陈曦,复旦大学人工智能创新与产业研究院教授、博士生导师。研究方向为科学智能 AI for Science 与大模型多智能体,致力于研究交叉学科中由领域知识驱动的概率建模和AI技术,以提高算法模型在交叉学科应用的泛化能力和可靠性。


