国际机器学习大会(ICML)是人工智能领域极具权威和影响力的顶级学术会议,长期引领人工智能、统计学、数据科学及相关交叉学科的前沿发展,是全球学术界展示和交流最新研究成果的重要平台。2026年,ICML将于7月6日至11日在韩国首尔举行。
复旦大学人工智能创新与产业研究院(以下简称“AI³院”)积极推动校内外深度交叉融合,联合上海科学智能研究院(以下简称“上智院”)、复旦大学附属华山医院、复旦大学附属中山医院、上海创智学院、清华大学、上海交通大学、南京大学等多家顶尖机构,在人工智能前沿技术领域取得重要进展,共计 11 项研究成果被 ICML 2026 录用。相关成果覆盖多模态表征学习、强化学习、神经算子与科学计算、生成模型对齐、时空建模与预测等方向。
以下为成果亮点速览:
一、TACO:从个体级别到群体级别,打破医学多模态“孤岛式”学习
论文标题:Beyond Instance-Level Self-Supervision in 3D Multi-Modal Medical Imaging
在医学影像自监督学习(SSL)领域,现有模型通常将每个病例视为孤立个体,依赖数据增强或掩码重建进行表征学习。这种“孤岛式”学习模式忽略了人类解剖结构天然的拓扑一致性——即无论个体如何变化,各器官间的空间相对位置始终保持稳定。这导致模型往往过度关注个体特征,而难以捕捉通用的医学先验知识。
为此,AI³院联合上智院、华山医院等机构联合提出了TACO(Topology-Aware Consistency,拓扑感知一致性)预训练框架。该方法首次将跨样本(Inter-instance)与跨模态(Inter-modality)的拓扑一致性作为自监督信号,通过挖掘解剖结构的“数字通式”来实现深层表征对齐。实验结果显示,TACO在7大下游多模态任务中表现卓越,并达到了当前先进水平。尤为突出的是,该模型在模态缺失的极端测试场景下也展现出极强的鲁棒性。
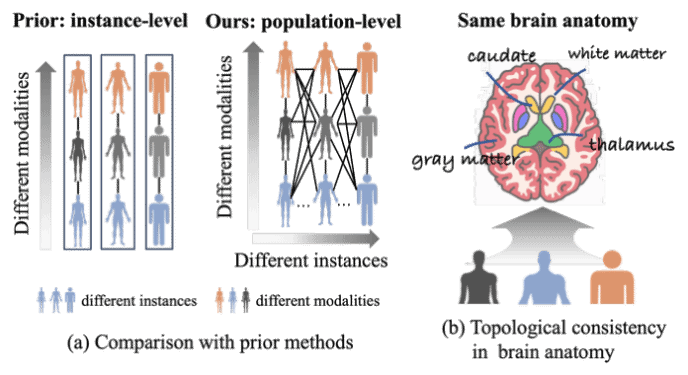
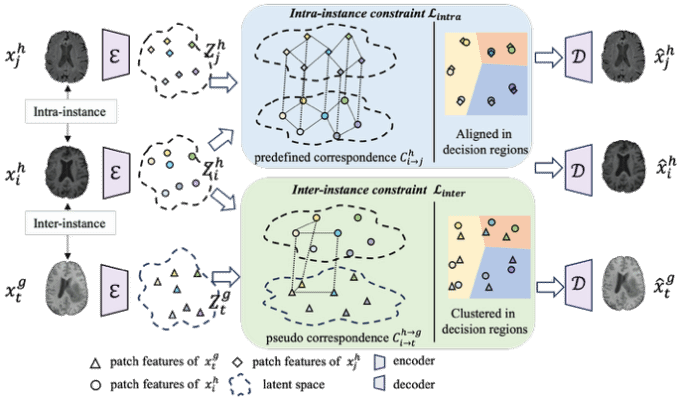
左图:人体脑结构的相对位置一致性 右图:TACO框架图
二、DisPPO:用分位数分布式强化学习提升大语言模型推理能力
论文标题:DisPPO: Quantile-Based Distributional Reinforcement Learning for Large Language Models
大语言模型在数学推理、代码生成和多轮工具调用等任务中,越来越依赖强化学习来释放复杂推理能力。但标准PPO等actor-critic方法通常让critic只预测一个标量价值,即累计回报期望,容易丢失方差、多峰性等信息,在稀疏或二值奖励下造成价值估计不准、信用分配偏差和训练不稳定。为此,论文提出DisPPO,将非参数分位数回归融入PPO,用分布式critic建模完整回报分布,并通过Distributional GAE生成更可靠的价值目标和优势估计。理论上,作者证明lambda-return Bellman算子与分位数投影组成的更新在Wasserstein度量下具有收缩性。实验覆盖Qwen、Llama模型,以及数学推理、Text-to-SQL和多轮工具增强推理等场景;结果显示,DisPPO在Avg@k、Pass@k等指标上持续优于PPO、GRPO、DAPO等基线,训练开销仅比PPO增加约4%,推理阶段无额外成本。
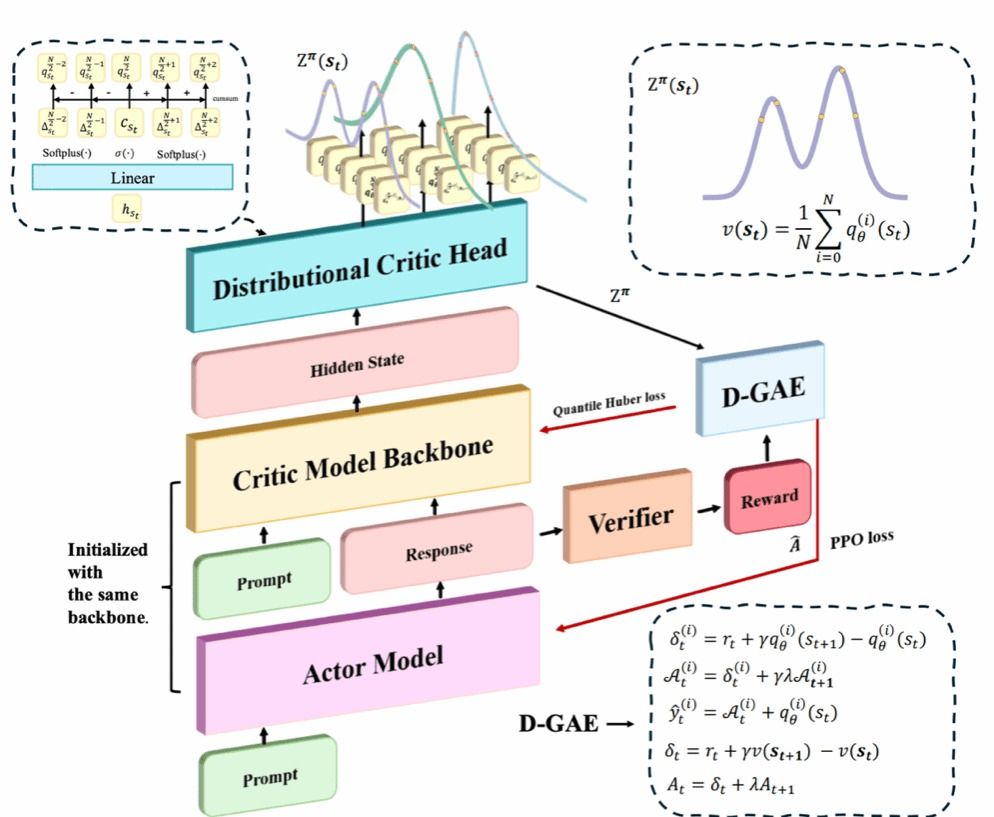
DisPPO方法总览:分布式critic输出回报分布,并通过D-GAE支撑PPO更新
三、CoEvol-NO:协同演化神经算子,几何感知与动态记忆兼得
论文标题:CoEvol-NO: State and Coordinate Co-Evolution with an Error-Driven Predictor-Corrector Paradigm for Neural Operator Transformer
针对现有PDE求解模型要么偏重几何细节、要么侧重动态记忆的局限,CoEvol-NO提出状态与坐标协同进化范式,让隐状态与网格信息双向更新、相互赋能,兼顾几何敏感性与物理演化记忆。模型融合经典预测-校正(PC)框架,以误差驱动精确梯度优化,理论上统一并超越传统残差与直接更新方式。同时保持线性复杂度,能高效处理大规模网格数据。在弹性力学、流体动力学等5项标准基准与汽车流场和气动设计2项工业任务中,CoEvol-NO均达到当前最优性能,具备强泛化能力,适用于科学计算与工业仿真场景。
不同交互隐空间交互范式与本文所提出CoEvol-NO框架细节
四、Prompt Reinjection:让文生图模型不再“遗忘”复杂提示词
论文标题:Prompt Reinjection: Alleviating Prompt Forgetting in Multimodal Diffusion Transformers
近年来,Stable Diffusion 3、FLUX、Qwen-Image 等多模态扩散Transformer(MMDiT)模型显著提升了文生图质量与复杂指令理解能力,但随着网络层数加深,文本分支中的提示词语义会被逐步削弱,尤其是数量、属性、位置关系等细粒度信息,导致模型在复杂组合提示下出现“漏生成”、“属性错绑”、“空间关系错误”等现象。
为此,AI³院联合上海创智学院、上智院等机构提出了Prompt Reinjection方法,将这一问题定义为MMDiT 中的Prompt Forgetting(提示词遗忘)。研究团队提出一种无需训练、仅在推理阶段生效的干预方法:浅层中仍保留较完整语义的文本特征,经过分布锚定与几何对齐后,重新注入到后续Transformer层中,从而持续强化提示词信息。该方法不需要更新模型参数,也不依赖额外训练数据,能够作为轻量插件应用于多种MMDiT文生图模型。
实验结果显示,Prompt Reinjection在GenEval、DPG-Bench、T2I-CompBench++等基准上均带来稳定提升,尤其在颜色属性绑定、数量理解、多对象组合和空间关系遵循等任务中表现突出,并在增强指令遵循能力的同时,基本保持甚至略微提升了图像整体质量。
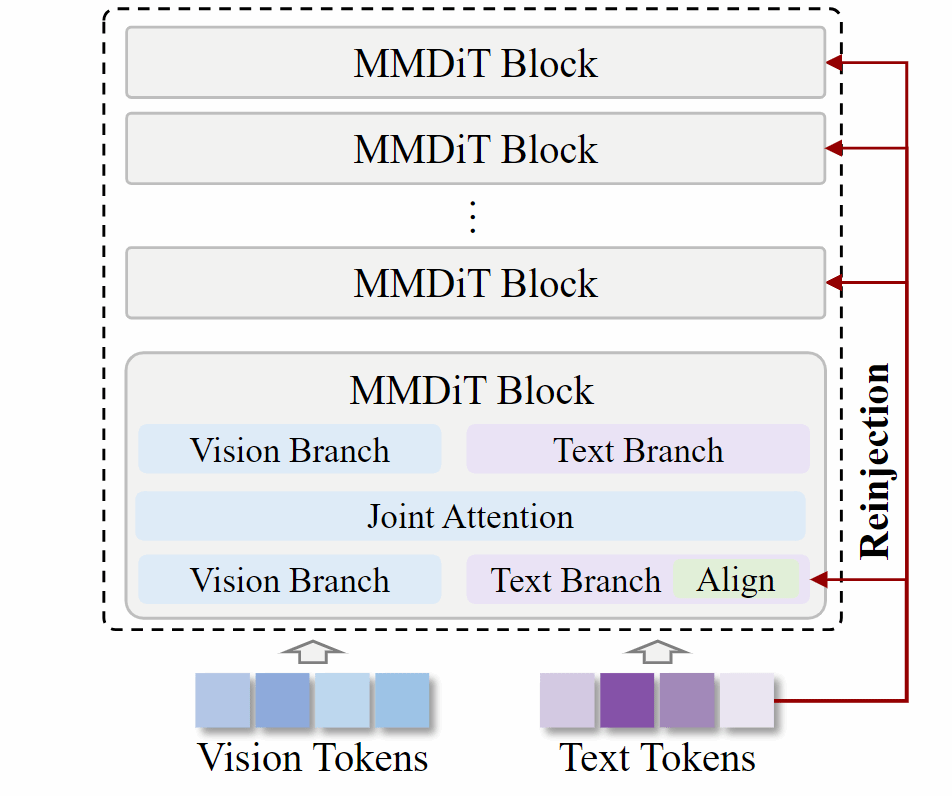
Prompt Reinjection框架整体结构:模型在推理过程中提取浅层文本特征,并通过分布锚定与正交Procrustes几何对齐,将其重新注入深层MMDiT block,从而缓解深层文本语义漂移与提示词遗忘
五、FLAG:让H&E病理图像精准预测空间基因“结构”表达
论文标题:FLAG: Foundation model representation with Latent diffusion Alignment via Graph for spatial gene expression prediction
空间转录组技术能够在保留组织空间结构的同时测量基因表达,是研究肿瘤微环境与疾病机理的重要工具,但其测序成本高、通量受限。从临床常规可获取的H&E全切片病理图像直接预测空间基因表达,已成为大规模分子分析的关键方向。然而,现有方法多将基因表达建模为逐基因的独立标量回归任务,仅以PCC、MSE等点对点指标进行评估,忽视了基因与基因调控网络、基因与空间分布等核心生物结构,难以支撑通路分析、空间域识别等下游任务。
为此,AI³院联合上智院、上海交通大学、中山医院提出了FLAG方法,将该任务重新定义为“结构化分布建模”问题。研究团队首先揭示了高维基因空间中存在的“基因维度诅咒”——节点与边联合图扩散在基因数量增加时会快速崩溃;进而提出以空间图编码器(Spatial Graph Encoder)建模点对点拓扑关系,作为条件信号引导基因维度的潜空间扩散过程,并通过与预训练基因基础模型(GFM)的表征对齐,注入稳健的基因与基因结构先验。同时,研究提出了基因结构相关性(GSC)与空间结构相关性(SSC)两项新指标,系统衡量生成结果的生物结构保真度。在HEST-1K数据集上,FLAG在PCC/MSE等点对点精度保持竞争力的同时,结构保真度指标显著领先现有判别式与生成式方法,能有效恢复基因调控网络与空间表达模式。
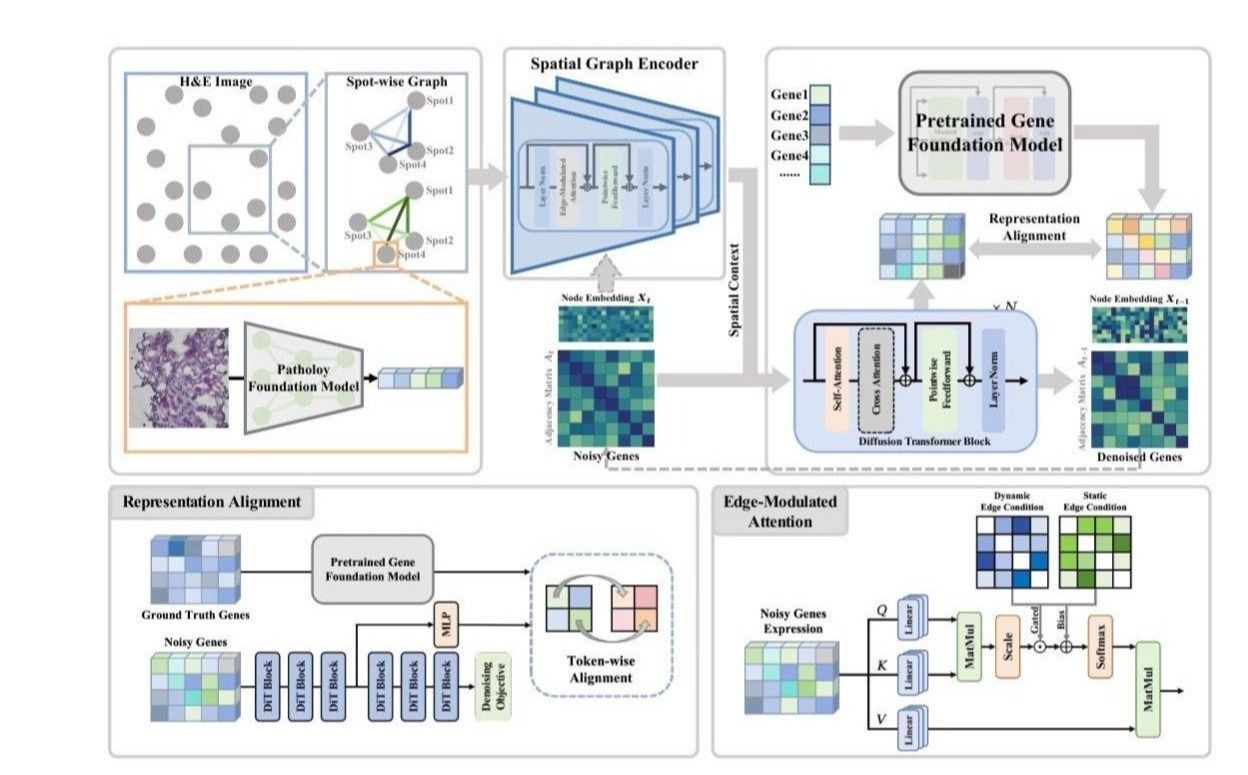
FLAG框架整体结构:左侧的空间图编码器整合H&E视觉特征与点—点拓扑关系,右侧的扩散Transformer在空间上下文条件下对基因表达进行去噪,并与预训练基因基础模型表征对齐
六、DistFlow:完全分布式RL框架,突破LLM后训练扩展瓶颈
论文标题:DistFlow: A Fully Distributed RL Framework for Scalable and Efficient LLM Post-Training
强化学习已成为提升大语言模型推理能力、对齐能力与复杂任务表现的重要后训练环节,但现有RL训练框架在大规模集群上仍常受制于中心化控制器。单节点既要调度执行逻辑,又要负责样本、rollout、奖励与梯度相关中间数据的收发,随着GPU数量、上下文长度和批量规模增长,通信与I/O开销会快速放大,造成调度等待、资源空转,甚至影响系统稳定性。
DistFlow提出一种面向LLM后训练的全分布式RL框架,将控制流与数据流解耦:DAG Planner把算法流程转换为可执行任务链,DAG Worker在各GPU上独立推进推理和训练任务,Data Coordinator则通过分布式dataloader、databuffer、本地缓存、负载均衡和异步双缓冲管理数据生命周期。该设计消除了中心节点瓶颈,使不同并行策略之间的数据重分布更加高效,并为PPO、GRPO等复杂RL流程提供更灵活的表达方式。实验表明,DistFlow在多GPU扩展场景下具备接近线性的伸缩能力,并相比现有SOTA框架显著提升端到端吞吐,为大规模LLM后训练提供了更高效、可扩展的系统基础。
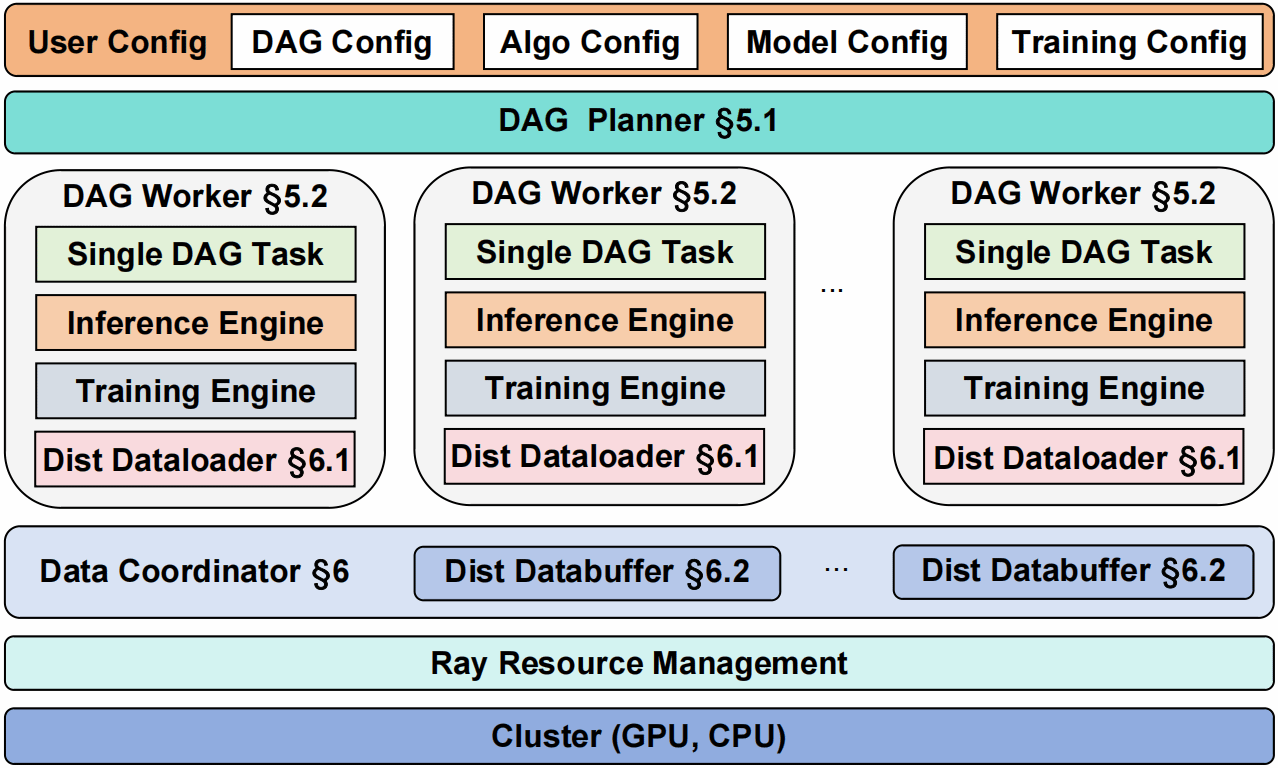
DISTFLOW完全分布式RL后训练框架Overview
七、SIPO:稳定并改进扩散模型偏好优化,让生成对齐更可靠
论文标题:SIPO: Stabilized and Improved Preference Optimization for Aligning Diffusion Models
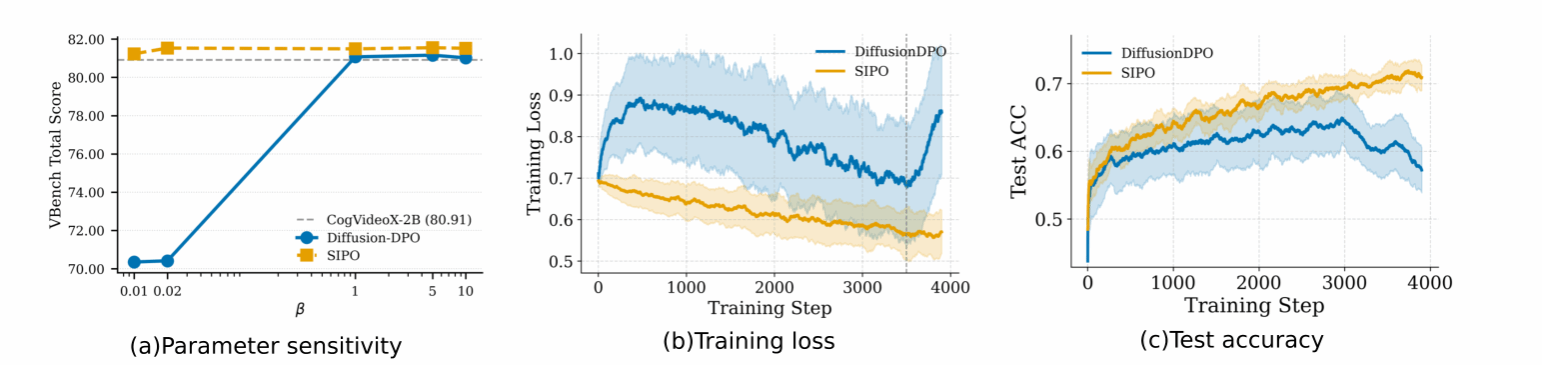
图像与视频扩散模型的偏好对齐通常依赖离线人工偏好数据,但Diffusion-DPO等方法容易受到两个问题影响:不同去噪步的梯度方差较大,导致训练对β等超参数高度敏感;同时,固定偏好数据与当前策略分布存在不匹配,易引发后期性能下降甚至训练崩溃。SIPO从扩散轨迹出发分析这一现象,发现低重要性权重的早期时间步是主要不稳定来源。方法上,SIPO先通过DPO-C&M对无效时间步进行裁剪和掩码,抑制噪声梯度;再引入时间步感知的重要性重加权,以校正离线偏差并突出有效更新。实验覆盖SD1.5、SDXL、CogVideoX-2B/5B与Wan2.1-1.3B,在图像和视频生成任务上均表现出更平滑的训练曲线、更强的β鲁棒性和更好的偏好对齐效果,为扩散模型稳定后训练提供了可扩展方案。
左图:人体脑结构的相对位置一致性 右图:TACO框架图
八、HybridOM:物理模型+数据驱动,提升长期预报稳定性与精度
论文标题:HybridOM: Hybrid Physics-Based and Data-Driven Global Ocean Modeling with Efficient Spatial Downscaling
全球海洋建模长期面临核心痛点:传统数值模式虽具备强物理可解释性,但计算成本极为高昂;而纯AI模型虽推理速度快,却极易在长期滚动预报中出现误差漂移,且缺乏基础物理约束。为此,AI³院联合上智院、清华大学等机构提出了HybridOM(一种融合物理模型与数据驱动的混合海洋模型)。该方法将可微分物理动力核心与神经网络置于统一的端到端框架中协同训练,让物理部分提供稳定演化骨架,AI部分精细刻画未解析过程。这种深度耦合避免了单纯的AI后处理,显著提升了长期预报的精度、稳定性与物理一致性。模型在全球业务预报及高分辨率区域降尺度任务中均表现优异。
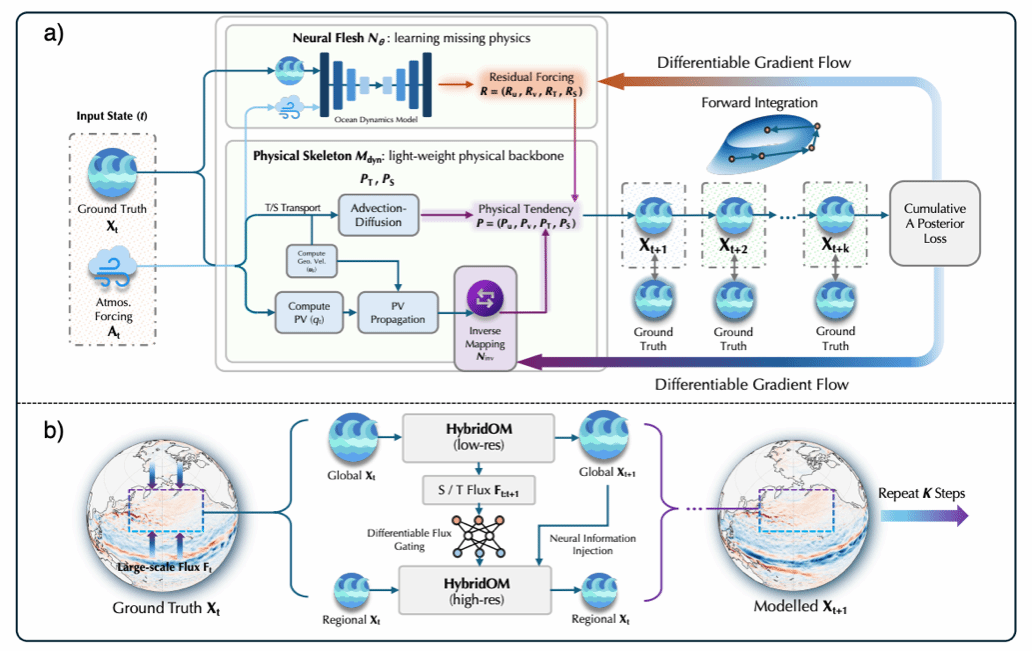
HybridOM:“物理规律约束” + “AI精细校正”的混合架构
九、NEST:基于未来宏观趋势引导,有效克服系统性噪声的时空预测新框架
论文标题:Nested Spatio-Temporal Time Series Forecasting
时空预测(STF)技术在城市交通管理、极端天气预测等现实智能系统中发挥着至关重要的作用,但当前该领域在复杂非平稳条件下仍面临诸多核心痛点:现有方法主要依赖历史空间先验,往往难以捕捉不断演变的动态时间相关性,且容易产生系统性误差;此外,当前普遍采用的细粒度、全图建模方法极易受到系统噪声的影响,随着空间尺度的扩大,模型容易学习到虚假相关性(spurious correlations),严重制约了预测模型的鲁棒性与长时预测能力。
为此,AI³院联合上智院、南京大学提出了NEST方法(Nested Spatio-Temporal forecasting,嵌套式时空预测),通过将未来的宏观区域趋势与微观的历史观测相结合,实现从抽象未来表示到细粒度预测的自上而下的显式引导。该方法创新性地利用基于谱聚类的语义方法构建一致性区域,在过滤系统噪声的同时保留核心趋势;并设计了渐进式由粗到细的预测器,使模型能够利用趋势预测提前预判周期性偏移等动态异常情况。该框架在多个高维大规模数据集上均持续超越了现有基准(SOTA)模型,且其宏观状态的低秩特性大幅降低了计算成本。
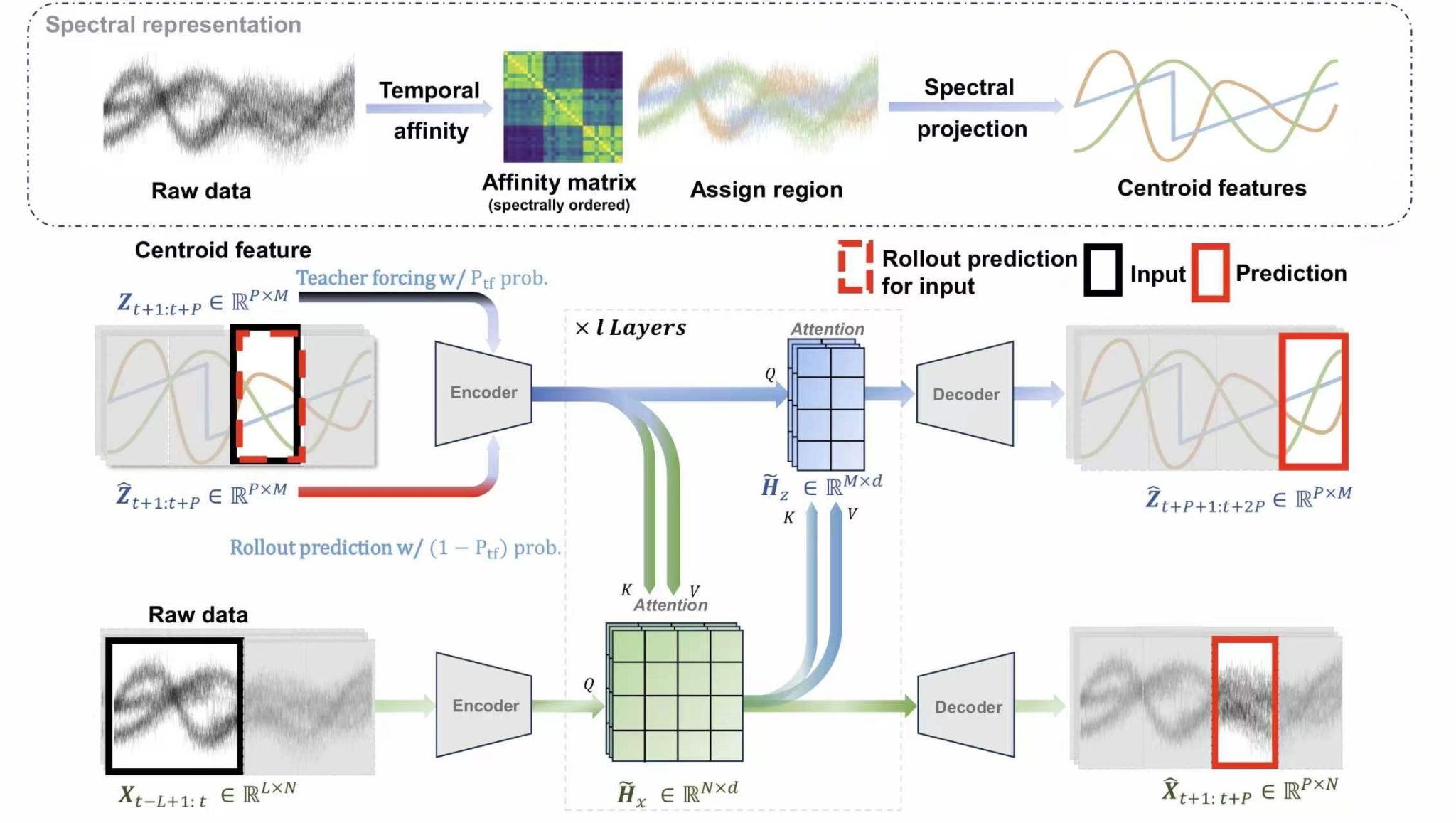
十、LineageFlow:从进化祖先出发的高保真蛋白质家族序列生成框架
论文标题:LineageFlow: Flow Matching for High-Fidelity Family-Aware Protein Sequence Generation
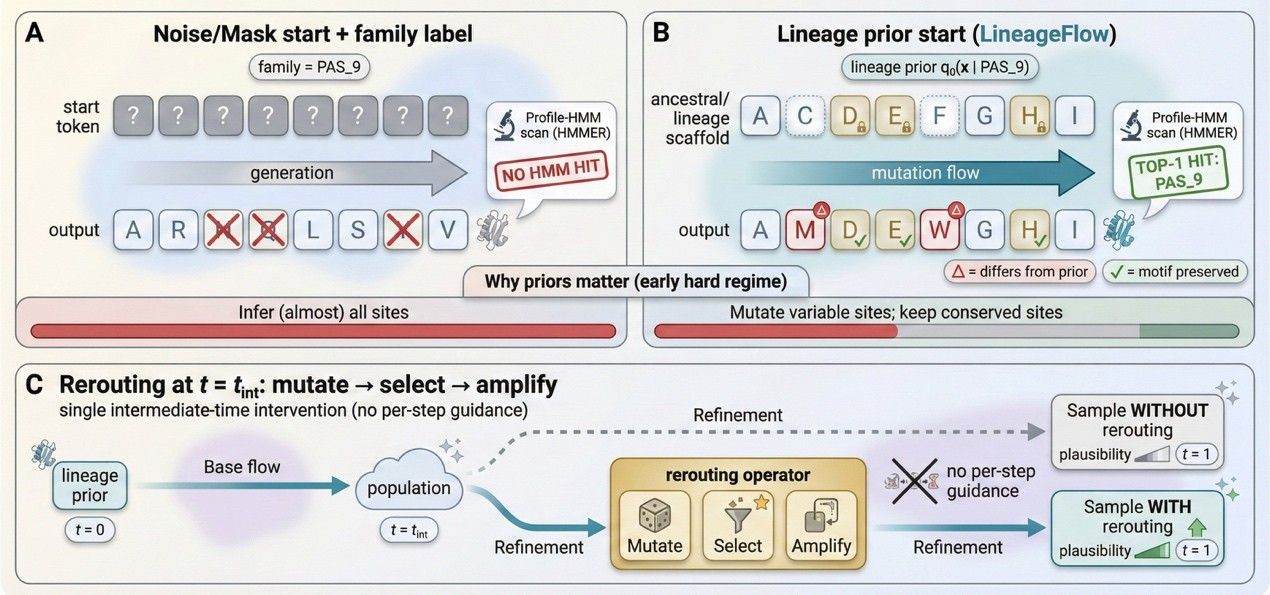
蛋白质工程需要在庞大的序列空间中寻找既具有生物物理合理性、又能保持目标家族或结构域特征的新序列。然而,现有离散蛋白质生成模型通常从均匀噪声或 mask token 出发,容易抹去进化形成的位置特异性约束;模型需要从头恢复保守位点和家族 motif,导致家族控制不稳定、可折叠性和生物合理性不足。
为此,AI³院联合上智院、上海创智学院、大连理工大学、哈尔滨工业大学(深圳)、Griffith University、Monash University 等机构提出 LineageFlow,一种面向蛋白质家族生成的 Dirichlet flow matching 框架。不同于从随机噪声出发,LineageFlow 基于多序列比对和祖先序列重建(ASR)构建家族特异的谱系先验,将生成过程理解为从“进化祖先 scaffold”到现代蛋白质序列的连续突变过程,从而在保留保守骨架的同时探索可变位点。研究还提出 rerouting 机制,在生成中间时刻执行一次“mutate–select–amplify”式干预,实现目标导向采样,无需在每一步引入昂贵的预测器指导。相比从 uniform/mask 初始化的基线方法,LineageFlow 在家族有效性、预测结构置信度、新颖性和多样性之间取得更好平衡:生成序列的目标家族识别准确率达到 95.3%,接近 held-out 天然序列的 96.6%。
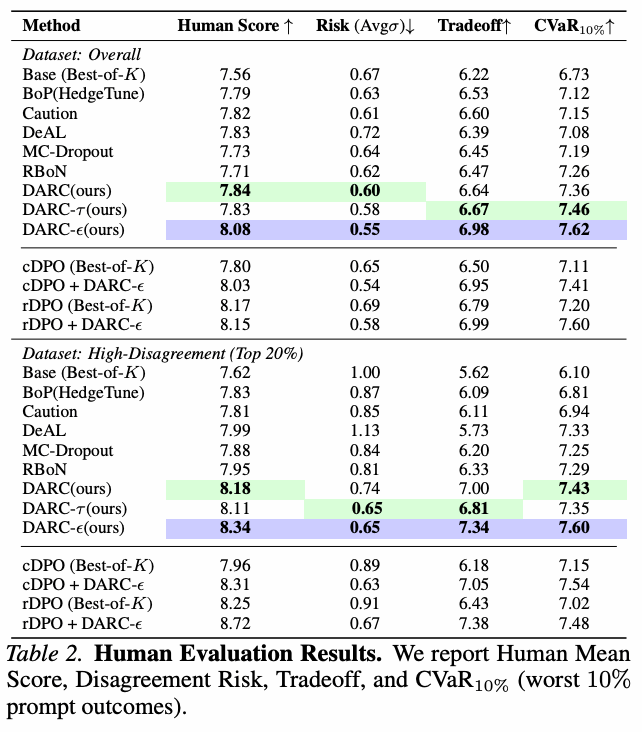
十一、DARC:面向偏好分歧的风险约束解码框架
论文标题:DARC: Disagreement-Aware Alignment via Risk-Constrained Decoding
人类偏好天然存在差异,但现有 RLHF、DPO 等偏好对齐方法通常将多样化反馈压缩为单一标量目标,容易掩盖标注者和用户群体之间的系统性分歧,导致模型在异质偏好场景下出现平均奖励过优化、尾部风险升高等问题。
为此,AI³院联合上智院提出 DARC,一种无需重训练的推理时风险约束解码方法。DARC 将回答选择建模为分布鲁棒、风险敏感的决策过程,利用多组偏好样本或可扩展的分歧代理信号,对候选回答进行重排序。该方法通过最大化 KL 鲁棒的熵型满意度目标,使模型在保持平均回答质量的同时,对高分歧、高风险回答保持适度保守;同时引入风险预算控制机制,可对相对于均值的熵型风险溢价进行约束或惩罚,便于实际部署中灵活调节稳健性与有用性。理论上,DARC 将风险约束解码与 KL 分布鲁棒优化和原则性悲观决策建立联系。实验表明,DARC 在多个对齐基准上能够降低偏好分歧和尾部风险,同时保持具有竞争力的平均质量,为异质人类反馈场景下的大模型稳健对齐提供了轻量化新方案。